

 Read Text
Read Text
Read Text Extension uses an external program or a web service to read text. Read the selection with Calc, Draw, Impress, Web Writer and Writer. Read the contents of the clipboard. Use speech synthesis to help to edit documents. Compare computer documen
latest release: 2024-11-17 08:29:45
Description
Read Text Extension lets an external program or web application read text from Writer, Calc, Draw, Impress, Web Writer or the system clipboard. If you use it to read text aloud, it can help you to edit your writing or to compare your document's text with a printed document. If you use it with a web application, you can translate your text to another language or check punctuation and grammar. It can help you to learn a new language or to find out how to say words you do not know. To use it, highlight some text. If you are using the word processor or the HTML editor, you can highlight several selections by holding down the Control key. When you have highlighted some text, select Tools - Add-Ons - Read Selection or click the Read Selection button on the tool bar. To read the system clipboard, select Tools - Add-Ons - Read clipboard.
If you can't read the screen easily, consider a system-wide accessibility solution for Apple OSX, Gnome, KDE or Microsoft Windows. If you have installed a system-wide accessibility solution, and it is activated, then you might not need this extension to read text aloud. You can use the Read Text Extension to read using a different language or voice, to save speech as an audio file, or send the text to a web application.
The Read text extension uses temporary files to send information to external programs. Depending on the security set up of your computer, other users or programs might be able to read the contents of files that the the extension or other external programs produce. If you are concerned about privacy, launch this add-on again with no text selected to replace the temporary file that contains the text you want to remain confidential. The paths and names of any temporary files directly created by the extension are shown in the Command and Script areas of the About... dialog.
Built-in speech synthesis
Read Text extension uses your computer platform's built-in speech synthesis application by default. For example, Linux uses espeak. Apple OSX uses say. Windows uses the system's SAPI5 voices. A Windows computer can read with a different voice or language if you install an additional SAPI5 voice.
External Programs
External programs can give your computer the ability to use different languages or voices. To use text to speech with a command-line based speech synthesis program like Festival or eSpeak on your computer, you may need to install extra speech files for your language and dialect. Custom voices will only work if they are installed. If you are using espeak with a recent release of Ubuntu Linux, you can install mbrola voices using the package manager. For other platforms, see the espeak-mbrola web page for instructions how to install voices from the mbrola project.
The external application can be any program you can start with a command line that can read plain text documents.
Web Applications
If you have an Internet connection, you can get started reading text aloud right away using different languages or voices without installing software by using the web application option. The extension uses your web browser or media player to play the selection. The main dialog of the Read Text Extension includes access to a web application for creating QR codes. QR codes are patterns of squares that embed text in a visual image so that mobile devices can quickly and reliably read information with a built-in camera. The application is powered by the Google Chart API. Read the on-line help for more information.
Screenshot

Additional documentation: http://code.google.com/p/readtextextension/wiki/About
Homepage: http://sites.google.com/site/readtextextension/
Repository: https://github.com/jimholgate/readtextextension
| Release | Description | Compatibility | Operating Systems | License | Release notes | Updated | |
|---|---|---|---|---|---|---|---|
| 0.8.90 | Improve Windows lexicon dialog latency and Linux Pied compatibility | 5.4 | Linux, Windows, macOS | LGPL | All Dispose of speech status file locks after a crash or an unexpected system reboot. Improve readability and update code. Linux Update default piper-tts lexicons. If you install the pied speech manager using the latest tar.gz file from the GitHub website in a local directory instead of using a flatpak or snap package manager, the extension can now find the location of the pied speech synthesis resource files. When using a local docker image of mimic3-server text to speech, ignore voices with improperly installed .onnx speech data. Use piper-tts by default when available instead of festival. Show the (SPD_READ_TEXT_PY) option whenever it would produce speech, even if your spd-say text to speech engine does not support the current language. Windows Update default piper-tts lexicons. Fix a delay when displaying the lexicon editor dialog. |
2024-11-16 17:23:30 | Download |
| 0.8.88 | LibreOffice 24.8.1 About dialog; Default lexicon abbreviations | 6.4 | Linux, Windows, macOS | LGPL | All Update the default English, French, German, Italian and Spanish lexicons to improve how untested speech models say common abbreviations. Update the About text for Piper text-to-speech. Fix the About Dialog failing to appear on a recent release that does not work as expected with the python3-scriptforge package. Remove orphan code. Linux Change the message in the pop up for restricted application environments that cannot use the system speech synthesis. Omit blocked options for sandboxed releases in the main menu. |
2024-09-20 17:27:41 | Download |
| 0.8.86 | Linux improvements | 6.4 | Linux, Windows, macOS | LGPL | All Improves python handling of soft links. Uses a consistent locally installed test sound. Linux AppImage Sound Test The extension now plays a sound file included with the extension when you tap the Test button in the About dialog. This means that the button works when you use a Linux AppImage. Pied The extension now creates a link to .onnx voice model binaries installed using Pied when the file passes a test that compares the md5_sum of the Pied version to the md5_sum of a current release of the .onnx model. A file can fail the test if the download was incomplete or the file was modified. In most cases, this means that setting up Piper text to speech in concert with Pied is easier and faster than ever. In the event that the file fails the test, the extension will download the current version. When you install Pied, the pop up notification shows a link to information about the Pied application instead of to the Piper samples web page. The document that shows in the About dialog when using the Python Piper Script includes specific information for installing Pied on enterprise Linux distributions like Alma, CentOS, Oracle, Red Hat and Rocky and for using Pied with a Flatpak on compatible Linux systems. |
2024-09-07 19:58:13 | Download |
| 0.8.84 | Bug fixes, updates and improvements to setup and advanced playback options | 6.4 | Linux, Windows, macOS | LGPL | All Enables playback on a wider variety of architectures and platforms. The Test button plays a background sound if the application has system permission using the BASIC uno platform, otherwise it is disabled. Windows When you click the Test button in the About dialog, the extension plays a test sound without opening it using an external application. This change makes the button behave like it does on other platforms. The Piper text-to-speech options in the main dialog previously included items that might not work reliably on Windows if the command contained a percent sign (%). These items have been renamed to use the word percent on Windows. Additionally, the Piper Windows options now include an --update False option to preview the current voice model information without triggering an update. Linux Attempts to find libav and gstreamer libraries on recent unofficially supported Linux architectures. Piper text to speech can use gst-launch-1.0 to play audio for platforms that require it as a playback method. If you install Pied speech manager you can still update the extension piper speech resource folder. Update the multilingual Snap welcome dialog to show a link to Mimic 3 speech synthesis information. When using a Windows version of the office application in Linux using a default installation of Wine, when you clicked the Test icon in the About dialog to check sound playback, the application would freeze. The extension now disables the sound playback test when using Wine. The extension now disables the sound playback test when using an AppImage because the current security settings do not allow playing a sound file located in the AppImage temporary working directory. MacOS The Test button uses the BASIC uno platform for the sound playback test. |
2024-08-30 19:54:19 | Download |
| 0.8.82 | Improve locally hosted speech like the Mimic3 client & piper-tts on Windows | 6.4 | Linux, Windows, macOS | LGPL | All Updated lexicons. When using localhost or local network speech tools, the extension strips non-printing characters to increase efficiency and to avoid unexpected vocalizations with some neural voice models. Windows Piper + VLC Client Piper is a fast, local neural text-to-speech system that sounds great. VLC is a free cross platform streaming media player. Piper is a neural text-to-speech system that you can install on computers with compatible processors. You can choose from many languages and voice models. When using a compatible release in Windows, the Piper text-to-speech python client now plays the selected text aloud without showing a command line window or a VLC player window by default. It now works the same as a Posix operating system does. You can show python information in a command line window in Windows using --update False or --update True in the command line options field of the main extension dialog. You can make a VLC player window visible by including a non-zero value while using the --player option. For example, you could change --player 0 to --player 7 in the command line options field to enable a graphical sound display. Linux Platforms Some Linux platforms use specific library directories for different processor architectures. The extension now checks the gstreamer directories for officially supported architectures using Debian 12 naming conventions. spaCy Library spaCy is a library for advanced Natural Language Processing in Python and Cython. On supported platforms, spaCy can intelligently divide long text strings into sentences. This helps online speech synthesis platforms return results faster. The extension uses an improved fallback method to divide long text strings into sentences if spacy does not work. See https://github.com/explosion/spaCy/issues/13550. |
2024-08-07 04:41:45 | Download |
| 0.8.80 | Updated the pronunciation editor dialog and help; Bug fixes and performance improvements. | 6.4 | Linux, Windows, macOS | LGPL | All Updated the pronunciation editor dialog and help. Bug fixes and performance improvements. Language and internationalization improvements. Update the URL for creating a QR Code online.s Linux The first run of the extension on a Wine client does not display an extension settings dialogue. Handle a Mimic3 timeout when a voice model has unexpectedly high latency or the Mimic3 server is not running. If the python spacy text analysis library is not available, then use sentence punctuation marks to divide long texts into a list so that networked text to speech works faster with long strings. Handle a potential Piper TTS runtime error after an application crash. MacOS Use MacOS custom python text to speech string replacements whether the application advanced experimental mode is enabled or not. Windows Handle a potential Piper TTS runtime error after an application crash. |
2024-07-22 00:10:29 | Download |
| 0.8.78 | Enhanced Piper Speech Synthesis compatibility including Rhasspy Piper Server | 6.4 | Linux, Windows, macOS | LGPL | All On supported releases, the About dialog shows the application python version information as a tool tip when the dialog displays a python script. This allows developers to determine what libraries and commands are appropriate for new python code. Remove unused code and some verbose comments. Fix bugs and improved legacy platform compatibility. Linux The latest version of the application installed with Ubuntu LTS now supports the SourceForge library, so it can show the application python major version, minor version and patch level as a tooltip whether using the normal system Office suite, a Snap release or a Flatpak release. When using the "(PIPER_READ_TEXT_PY)" --language (SELECTION_LANGUAGE_COUNTRY_CODE) "(TMP)" command, the About dialog suggests using the Pied app to install and manage Piper voice models. If you use the Pied app to manage Piper voice models after already having installed voice models manually, the Piper client no longer tries to create virtual links to replace hard linked files. Rhasspy Piper Server Rhasspy Piper is a fast, local neural text to speech system. A local network server version of Rhasspy Piper Server can serve a single voice model to different devices for a home network as an assistant to home automation devices or as a speech synthesis system for computer desktop applications that cannot run a locally installed piper program or model. This Rhasspy Piper network client will only work correctly if the language of the model that it serves is the same as the language locale of the user. Use "(NETWORK_READ_TEXT_PY)" "(TMP)". Use a specific local network address to access a Rhasspy server that you host on another computer in your home network. For example, with the default Piper server settings, you could use "(NETWORK_READ_TEXT_PY)" --url http://192.168.0.108:5000 --voice piper "(TMP)". When running the piper server in a command line window, it shows the following warning: WARNING: This is a development server. Do not use it in a production deployment. You can find out more about installing and using the server on the GitHub Rhasspy project) site. See also: https://www.youtube.com/watch?v=pLR5AsbCMHs Rhvoice Server Correct a default string value. |
2024-05-19 23:17:11 | Download |
| 0.8.76 | Bug fixes, help and performance improvements; Update Linux alternate package support | 6.4 | Linux, Windows, macOS | LGPL | All Bug fixes, documentation and performance improvements. Spanish help on supported platforms. Images of Dialogues in Help on supported platforms. When you enable Use Experimental Mode in your Office program, the settings are saved in a different file. Note: To accommodate the improved settings behaviour, when you update this extension, or the version of Office, the settings will revert to their defaults. Linux AppImage application settings are saved in a different file than when you are using the standard application. Snap support for Mimic3. Flatpak support for PiperTTS and Mimic3. Note: On supported architectures and platforms, the Pied application from the Snap or Flatpak App Store is an easy way to install and manage high fidelity PiperTTSvoices on your local desktop. You can listen to samples of Piper voice models using the online Piper samples page. About Pied Pied is a program for Linux distributions. When you first start the Pied program, it allows you to download the Piper speech synthesis program and compatible voice models. You can use Pied to choose the voice model that accessible programs like Firefox and Thorium ePub reader use to read text aloud. If a client program does not support selecting a particular voice from a voice model that includes several voices, then the program uses the first available voice. If Pied has downloaded a voice model in a different language, but you have not set it as the default voice, Read extension can use that voice instead of the default voice using "(PIPER_READ_TEXT_PY)" --language "(SELECTION_LANGUAGE_COUNTRY_CODE)" "(TMP)" in the command line options field. |
2024-05-03 22:37:10 | Download |
| 0.8.74 | Options to enable or deny experimental features; Windows Piper support. `(RESET_ALL)` feature in main dialog` | 6.4 | Linux, Windows, macOS | LGPL | All Allow or deny access to third party scripts depending on the Office version and whether “Enable experimental features” in the “Options” or “Preferences” menu is enabled. (Resolves GitHub Issue 24). Bug fixes and performance improvements. Require Python 3.8 or higher to enable “Neural” text to speech platforms. (RESET_ALL) feature in main dialog. MacOS “Enable experimental features” replaces “Festival” in the main menu. The MacOS system security settings now do not allow an extension to initiate a third party program like VideoLAN VLC, even if you have enabled “Enable experimental features” in the “Preferences - Advanced” menu. As a consequence, the options to save audio transcripts only include formats that are native to the platform. Windows The Rhasspy project released a Windows pre-release of it's Piper TTS software. Starting with Read Text 0.8.74, the extension supports it as an experimental feature on Windows x86_64 or amd64 machines. You need to make sure that you have installed 64 bit versions of the most recent versions of piper, VideoLAN VLC Media Player and python, and that these programs are in your system paths. You need to enable “Enable experimental features” in the “Options - Advanced” menu of the office application. The details are on GitHub. LinuxGstreamer Gstreamer paths are correct for computers using Debian 12 on legacy 32 bit Intel processors. Gstreamer now exports open format files like .opus, .spx and .ogg using a standard format without metadata. The encoding rate for .opus is optimized for quality whereas .spx uses small file sizes that work well for speech recording. Wine Using the extension with Wine 9 works with supported computer architectures. Because of differences between Windows and Wine for Linux platforms, latency is higher and the risk of distorted speech is higher than it is on authentic Windows systems or on Linux distributions. To use Piper TTS with Wine 9, install the 64 bit version of VideoLAN VLC and make sure that piper.exe is in the system path. See the comments for Windows. If you have voice models on the host Linux system, you can create a symbolic link in your host system to where Wine would store voices in it's directory. (i. e.: If you use the default settings, the command might look like ln -s ${HOME}/.local/share/piper-tts/piper-voices ${HOME}/.wine/drive_c/users/${USER}/AppData/Roaming/piper-tts/piper-voices). To install Piper voices only in the Wine user directory, use Tools > Add ons... > Read Text... and include an option that includes a voice model for the current language and the --update True key/value string. |
2024-02-24 01:17:56 | Download |
| 0.8.72 | Simplify first run. PLS lexicon export. Linux Piper replaces Larynx | 6.4 | Linux, Windows, macOS | LGPL | All On supported platforms, the first time you select text and click the toolbar button, the extension reads the selected text aloud using default settings instead of showing a dialogue. This makes it quicker and easier for new users to get started. Bug fixes and performance improvements. On supported platforms, enable export of x-sampa or ipa International Phonetic data using an XML format. The World Wide Web Pronunciation Lexicon Specification (PLS) is a standard way to describe pronunciation. For example, accessible ePub books can use PLS files to help reading systems pronounce uncommon words, place names and personal names correctly. The PLS uses alias to refer to a sequence of words. For example, writers can use “W3C” to mean “World Wide Web Consortium”. The W3C Pronunication Lexicon Specification uses phoneme to refer to an alternate spelling that uses a phonetic code. IPA uses /ˈkænjən/ for canyon. The strings can include special reserved IPA characters. X-SAMPA uses ["k{J@n] for canyon. The strings use standard ASCII code. Specific language models might only support phonemes that are widely used in the language. As a result, they might not be able to pronounce some words correctly. Specific language models might require a specific phonetic code - like IPA or X-SAMPA. Each exported XML file includes only one regional pronunciation. Editors and publishers can optionally edit the file to specify pronunciation of specific words for other regions using a code editor. MacOSThe MacOS system allowed access to the phoneme editor even when phoneme substitution was not available using the default AppleScript scripting language. Now the extension disables right-click accessto editing phonemes from the tools button of the About dialog if python3 is not enabled. MacOS only supports phonemic substitution if python3 is enabled in the main dialog. Some MacOS users might need to agree to the current “Xcode and Apple SDKs license” to use some features of this extension that use python code. You can view and agree or reject the Apple license agreement by entering the following in a terminal window: sudo xcodebuild -license. Editing and using phonemic substitution requires you to enable/usr/bin/python3 in the external program field of the main dialog of the extension dialog instead of the default /usr/bin/osascript. Windows The file dialog for the saving a phoneme file did not suggest a file name. It now suggests a file name. The extension can use StarBasic to generate SAPI text to speech if the Windows system wscript.exe program is not available. LinuxMake it easier to add and select piper-tts voice models. Linux Piper replaces Larynx, because Larynx contributors can no longer update Larynx code. The main menu includes some suggested voices for different languages. When piper-tts is available, the main menu includes a menu item to update piper-tts metadata to include new languages and voices. |
2023-11-06 07:15:47 | Download |
| 0.8.70 | Bug fixes; Linux `piper-tts` support. Speech rate support for Linux `mimic3` | 6.4 | Linux, Windows, macOS | LGPL | All Bug fixes. Lexicon updates. Linux Support for LibreOffice 7.6.0 AppImage Debian 12 and Fedora 38 clients use pw-cat from the pipewire-bin package to improve the latency of audio playback on low end systems. Speech toggling worked correctly with localhost speech servers on Ubuntu 22.04 LTS but not with Debian or Fedora. Now when using Debian 12 and Fedora 38 and related platforms, the click to toggle off function of the application works as expected with system packages and AppImage packages. Remove Festival voice support from the docker OpenTTS client, because the OpenTTS server does not work consistently with Festival across all supported platforms. OpenTTS Flite voices are a fast and reliable alternative. Change the client’s timeout terminal troubleshooting message when a speech server unexpectedly fails. Mimic 3The Mimic 3 localhost client now supports changing the speech rate. Piper TTSPiper TTS is a fast, private local neural text to speech engine. Users can create or refine voice models based on a recording of a voice. This client uses the piper engine to read text aloud using Read Text Extension with your office program. Piper samples Instructions Download voices Read Selection... Dialog setup:External program: /usr/bin/python3 Use the first available voice. "(PIPER_READ_TEXT_PY)" --rate 100% --language (SELECTION_LANGUAGE_CODE) "(TMP)" Use a particular model (auto5) and speaker (45): "(PIPER_READ_TEXT_PY)" --voice auto5#45 --rate 75% --language (SELECTION_LANGUAGE_CODE) "(TMP)" Install piper-ttsIf you are not online, then you cannot download voice models or configuration files. Once they are installed, piper handles speech locally. Binary releaseThe binary release is fast. The most recent binary piper executable program included in a piper archive for your computer's specific processor type. For example, piper_amd64.tar.gz works with x86_64 processors. For example, for the piper_amd64 1.2.0 release, use the following: python3 -c "import os;os.makedirs(os.expanduser('~/.local/share/piper-tts/'))" wget -O ~/piper_amd64.tar.gz https://github.com/rhasspy/piper/releases/download/v1.2.0/piper_amd64.tar.gz tar -xf ~/piper_amd64.tar.gz -C ~/.local/share/piper-tts/ ln -s -T ~/.local/share/piper-tts/piper/piper ~/.local/bin/piper-cli ~/.local/bin/piper-cli --version Use the following if you do not plan to also install the python release: ln -s -T ~/.local/share/piper-tts/piper/piper ~/.local/bin/piperPython releaseThe python pipx package has higher latency, but the piper script simplifies automating downloading the required onnx data and json configuration files. Some Linux platforms use python versions that are incompatible or only partially compatible with the pipx stable release of piper-tts. Install the following packages: python3-pipx espeak-ng-data Then use pipx to install piper-tts pipx update-all pipx install piper-tts pipx ensurepath piper -h Audition and download a voice modelYou can check the voice models online. Review the voice model samples. The first time you use this client, it will set up a directory to store piper voice models (onnx) and configuration files (json). ~/.local/share/piper-tts/piper-voices You can download the voice and configuration files for various languages and regions following the link on the piper-samples web page. Move the onnx and json files to the local piper-voices directory. Read the README file in the directory for more information about using voice models for other languages and regions. System-wide installationIf you want every account on a single computer to have access to piper then locate the contents of piper_amd64.tar.gz or the equivalent for your computer architecture in a directory that every account has read access to and link the piper application from the archive to a location that is in every user's PATH environment. For example, sudo ln -s -T /opt/piper-tts/piper/piper /usr/local/bin/piper If this piper client does not find user installed models and configuration files, it looks for global models and configuration files in: /usr/local/share/piper-voices Users can access the model in the directory from the client dialog using: "(PIPER_READ_TEXT_PY)" --voice auto0#0 --rate 100% --language (SELECTION_LANGUAGE_CODE) "(TMP)" If your Linux distribution includes packages to link speech-dispatcher with piper-tts, then you can configure the speech-dispatcher platform to use piper-tts: "(SPD_READ_TEXT_PY)" --language "(SELECTION_LANGUAGE_CODE)" "(TMP)" Piper TTS Links About Piper TTS Piper Samples Piper Voices Thorsten Müller - Piper Voice Training |
2023-09-01 16:04:31 | Download |
| 0.8.68 | Updated `localhost` network speech platforms, MacOS & Linux bug fixes | 6.4 | Linux, Windows, macOS | LGPL | All Bug fixes and code readability improvements. Lexicon updates. Linux Updated localhost network speech platforms. The Mimic3 python library includes a gender table for supported models. You can instruct the program to ignore gender by using auto as the voice in the place of male or female. Enable the OpenTTS network speech synthesis on supported platforms. OpenTTS can use a variety of Linux speech synthesis libraries. You can install OpenTTS using docker on supported Linux platforms. OpenTTS unifies access to multiple open source text to speech systems and voices for many languages. Handle out of range voice id more consistently across localhost speech engines using modulus math. (i. e.: handle --language "(SELECTION_LANGUAGE_COUNTRY_CODE)" --voice "FEMALE10" when there are only 6 female voices currently available.) MacOS Fixed a python network speech synthesis regression, so python users can use network speech as a fallback for an unsupported language. |
2023-07-16 02:36:56 | Download |
| 0.8.66 | Support python3 pipx and additional libraries; Mimic3 server and Coqui AI serverLinux support | 5.4 | Linux, Windows, macOS | LGPL | All Bug fixes Updated lexicons MacOS Support for pipx (python pip using a virtual environment manager) Better support for user installed pip3 libraries Linux Support for pipx (python pip using a virtual environment manager). The pipxlibrary allows you to install and run python applications in isolated environments. The pipx program replaces pip3 in Debian 12 and its derivatives. Support for developer-oriented speech servers – Mycroft Mimic3 and CoquiAI TTS. You can tell if the speech server is installed correctly if you can open a sample speech synthesis page in your web browser. Use either server using an option that includes the string "(NETWORK_READ_TEXT_PY)" --language "(SELECTION_LANGUAGE_COUNTRY_CODE)" "(TMP)" in the Read Text Extension main dialog. You can install spacy with pipx to reduce latency when using a local speech server with a long text selection. The spacy python library can intelligently split up long text selections into sentences. Mycroft Mimic3Mimic3 is a fast local neural text to speech engine for amd64, arm64 and armv7l processors. It’s available as an apt package for Debian or as a docker.io image. The documentation tells how to set up a Mimic3 server using the Debian deb package manager or a docker.io application. To test it out, use mimic3-server Once installed you can test the server and install voice models by using a web browser to open a local webpage. If you use the Read Text Extension dialog as described above, then the extension will try using mimic3-server first. If you prefer normally the system’s speech-dispatcher voice as your main speech manager and Mimic for a secondary language, then use "(SPD_READ_TEXT_PY)" --language "(SELECTION_LANGUAGE_COUNTRY_CODE)" --voice "AUTO" "(TMP)" in the main menu. The "AUTO" voice name enables using the local mimic3-serverfor languages that the system’s speech-dispatcher does not support directly. The instructions for Mimic3 describe how to set up speech-dispatcher to use mimic3 by default. In this case, you can omit the AUTO voice (i. e.: "(SPD_READ_TEXT_PY)" --language "(SELECTION_LANGUAGE_COUNTRY_CODE)" "(TMP)") Read Mimic3 documentation and requirements for more details. CoquiAI TTSCoquiAI TTS engine is a deep learning toolkit for Text-to-Speech, mainly intended for use in research and production services. It includes a tool called tts-server that uses a local http service to allow web browsers and other programs that can connect to a local http server to convert text to speech. With the Read Text Extension network client you can check how new TTS models work with real world text. See tts-server --help A server instance only serves one model at a time, but you can specify the language by selecting a model that includes the iso language code for the language in the model name. See tts-server --list_models If you do not specify a model, then the server uses a female en-US model by default. Example server commands Default tts-server English tts-server --model_name tts_models/en/vctk/vits French tts-server --model_name tts_models/fr/css10/vits Check the documentation for specific hardware and software requirements. Some voice models require system files that are not explicitly stated in the documentation. Best practice is to use TTS python libraries in a virtual environment by installing TTS using venv, pipx or docker.io tools. You can use the web page interface to test if the server works and if there are any problems with a particular voice model. If a model does not work at all, run the tts-server program in a command window and note any error messages that mention missing libraries or system packages. Read Text Extension's python TTS client uses a few additional system packages - python3-bs4, python3-pip, pipx and espeak-ng. On supported Ubuntu distributions you can use: sudo apt-get install python3-bs4 python3-pip pipx espeak-ng To troubleshoot the server and the client, you can see information and error messages when you run the server and office program using separate terminal windows. Server tts-server --model_name tts_models/en/vctk/vits Client /usr/bin/libreoffice Enable Coqui.ai TTS server in the office program using the main Read Text Extension dialog with "(NETWORK_READ_TEXT_PY)" --language "(SELECTION_LANGUAGE_COUNTRY_CODE)" "(TMP)" If you prefer normally the system’s speech-dispatcher voice as your main speech manager and tts-server for an unsupported secondary language, then use "(SPD_READ_TEXT_PY)" --language "(SELECTION_LANGUAGE_COUNTRY_CODE)" --voice "AUTO" "(TMP)"` Read CoquiAI TTS Documents and CoquiAI GitHub pages for more details about the CoquiAI project and tts-server. |
2023-05-28 23:37:39 | Download |
| Read Text 0.8.64 | Bug fixes; Additional docker tools - MaryTTS & Rhvoice-rest; Pronunciation editor | 5.4 | Linux, Windows, macOS | LGPL | All Bug fixes Additional docker tools - MaryTTS & Rhvoice-rest Pronunciation editor How to edit localized pronunciationWhen you use this extension with a compatible app, you can replace incorrectly pronounced words and acronyms with a string that the system speech synthesizer can read correctly. "g":"Metis","p":"[met-tea]" "g":"Read Text Extension","p":"reed text extension" Select a word that you want to change the pronunciation (i.e.: "Metis") Select Tools - Add Ons... - Read Text Extension Click About... On MacOS Command + Click the Tools Icon, on other supported platforms, right-click the Tools Icon In the Read with an external program (macos_say) field enter how you want to say the mispronounced word (i.e.: "[met-tea]") Click Apply. You can find an example of a lexicon table on GitHub To download an online lexicon table, Command + Click or right click the Open button and verify the URL. Windows LibreOffice 7.5 allows you to download or create localized lexicons to specify how text to speech says local words or peoples' names. On Windows, no speech is changed until you manually change the pronunciation of at least one word. MacOS When using a supported release of MacOS, LibreOffice 7.5 allows you to download or create localized lexicons to specify how text to speech says local words or peoples' names. Linux Support additional docker text to speech programs including MaryTTS and Rhvoice-rest. On supported platforms and releases, Apache OpenOffice and LibreOffice allow you to download or create localized lexicons to specify how text to speech says local words or peoples' names. |
2023-03-15 04:55:22 | Download |
| 0.8.62 | Updates for MacOS 13.0.1 and Debian Linux 11.5 plus documentation updates and bug fixes | 5.4 | Linux, Windows | LGPL | WindowsClicking multiple times quickly on the main button on a legacy Windows system will not cause the application to open the Basic editor with an error message because of a request to delete a lock file that no longer exists. MacOSMacOS 13 (Ventura) includes many new multilingual voices. Now, if you use /usr/bin/python3 as the application in the main extension dialog, you can select different voice profiles like “male2” or “female1” that select a male or female profile for every language that has both male and female voices. On MacOS, python checks if Fiona and Lee are actually installed before allowing them as a voice option. These two voices appear in the say -v '?' response, but they are not installed by default in all regions. LinuxSupport the larynx-server speech synthesis platform. Since the larynx-server Application Programming Interface (API) uses the http network protocol, supported snap and flatpak versions of office software that block speech-dispatcher can now use high quality speech synthesis with Read Text Extension. The larynx package includes many high quality voices. You can manage languages and voices using a web browser pointed to a locally hosted web page. Supported languages include Dutch, English, French, German, Italian, Russian, Spanish, Swedish and Swahili. On Debian 11.5 compatible Linux platforms, you can use cinnamon-settings startup, gnome-tweaks or another similar application to set up larynx-server to automatically start up after 10-15 seconds when you log in. For testing purposes, you can also start the server by entering the larynx-server command in a terminal window. |
2022-12-01 23:50:04 | Download |
| 0.8.60 | Bug fixes and support. Supports more .wav to .mp3 converters. | 5.4 | Linux, Windows, macOS | LGPL | All PlatformsBug fixes and support. Supports more .wav to .mp3 converters. WindowsFix VLC exports. Omit Flac export – sometimes created a file with length of zero. Do not ask for metadata with VLC because VLC does not include metadata. Python update readtexttools.py includes a command for Windows Media Player to play mp3 files. MacOSMacOS Monterey 12.6 uses python 3.9.6, so the release includes a compatibility update. LinuxImproved audio file export support for lame. Versions of LibreOffice released as appImages require ffmpeg or lame to be able to export .mp3 files. This release supports lame in addition to ffmpeg. If you install one of these programs, the main menu includes an option to include a poster image with the .mp3 audio file. Playback on Linux. Resolves Debian Linux GitHub Issue 21. When using plain single and double quotes with pico2wav or speech-dispatcher, the speaker would pronounce the character coding for the characters on some systems. This update resolves this issue. |
2022-10-02 21:52:25 | Download |
| 0.8.58 | Bug fixes and performance improvements. | 5.4 | Linux, Windows, macOS | LGPL | Bug fixes and performance improvements. Works on legacy i386 32 bit systems. Details... |
2022-08-24 17:09:52 | Download |
| 0.8.56 | Bug fixes for LibreOffice 7.3. Feature update for Ubuntu Linux 22.04 LTS. | 3.3 | Linux, Windows, macOS | LGPL | This release includes bug fixes for LibreOffice 7.3.2.2 and current language frameworks for Ubuntu Linux and Fedora Linux. All PlatformsGitHub Issue 19 March 30, 2022 is resolved. LibreOffice 7.3.2.2 does not display a dialog saying “Argument not optional” and stop. Copyright information for on-line service providers is included. Ribbon Enabled - The extension can display buttons on the LibreOffice ribbon toolbar. Before you select View – User Interface… – Ribbon, note that if you choose to use the ribbon, you will have to perform two clicks to read text aloud; one to select the Extensions tab and one to click the Read Selection… button. WindowsYou can add the ability to create compact audio files without personal metadata if you install the desktop version of VideoLan VLC. The Windows Store version of Apple iTunes also works now, but the files it creates are larger because they include metadata information and an image. MacOSYou can add the ability to create compact audio files in open formats like ogg and opus without personal metadata if you install the desktop version of VideoLan VLC. File export works in both legacy and current versions of MacOS. LinuxBoth Fedora and Ubuntu can read text aloud when using a current Try Ubuntu or Try Fedora USB stick or DVD. If you download an AppImage of LibreOffice to try out a different version, then you can probably use most functions of the extension, depending on the exact version of LibreOfficeyou install. It’s been verified with LibreOffice 7.3.2.2. The python script for Festival now lets you use Flite as an alternative to a full installation of Festival for a compact low latency English voice. If you have installed the necessary packages, the extension can play jtalk voices in Japanese. When you create a media file, a Fedora or Ubuntu Gnome desktop pops up an information message when the program finishes creating the file. |
2022-05-02 22:38:02 | Download |
| 0.8.52 | Update web links and code for MacOS 11 | 6.0 | Linux, Windows, macOS | GPL | * Works on MacOS Big Sur * Updated sample web links |
2021-10-07 16:44:20 | Download |
| 0.8.44 | Bug fixes for LibreOffice 6.4.0.3. | 6.0 | Linux, Windows, macOS | GPL | Bug fixes for LibreOffice 6.4.0.3. Remove VLC from list of compatible players and convertors for Linux because the functions that the extension depended on no longer work. Improve readability of code and correct syntax errors. |
2020-03-05 23:09:51 | Download |
| 0.8.34 | Bug fix | 4.4 | Linux, Windows, macOS | GPL | Bug fix Incorrect StarBASIC syntax: missing closing parenthesis With a recent changes in LibreOffice StarBasic parser, it now doesn't silently accept a missing closing parenthesis anymore (as it did before). This release adds missing closing parenthesis. |
2020-03-05 23:09:50 | Download |
| 0.8.42 | Simplify the settings dialogue for LibreOffice 6.2 | 4.4 | Linux, Windows, macOS | GPL | LibreOffice 6.2.3 for Windows, MacOS and Linux does not allow the extension script to restore the last displayed option for the dialogue; therefore the dialogue always defaults to the first available option. By disabling the festival option if the festival program is not installed, the dialogue defaults to External Program, the most commonly used option on Windows and MacOS. Windows and MacOS commonly can use multilingual system voices, therefore you do not need Festival unless you require a voice for a region that are not available in the system voices catalogue The scripts for setting up the dialogue use with notation to make the code more readable. The main dialog uses a compatible group tag for the option radio button and uses a tab order that groups the radio buttons together. |
2020-03-05 23:09:49 | Download |
| 0.8.36 | Improved multilingual support on Windows 10 | 4.4 | Linux, Windows, macOS | GPL | Improved multilingual support on Windows 10. Update tts_wscript.vbs for Windows Speech API (SAPI 5) - selecting XM… |
2020-03-05 23:09:49 | Download |
| 0.8.32 | Update links; fix support for Gstreamer sound playing in Linux. | 4.2 | Linux, Windows, macOS | GPL | Update links; fix support for Gstreamer sound playing in Linux. | 2020-03-05 23:09:48 | Download |
| 0.8.40 | AppImage support, updated documentation, bug fixes and performance improvements. | 4.4 | Linux, Windows, macOS | GPL | Make compatible with the AppImage format (AppImage is a format for distributing portable software on Linux without needing superuser permissions to install the application.) Update help, links and comments. Bug fixes and performance improvements. Details |
2020-03-05 23:09:48 | Download |
| 0.8.38 | Main tool bar icon resized for LibreOffice 6; Ubuntu 18.04 speech synthesis compatibility. | 4.4 | Linux, Windows, macOS | GPL | Bug fixes and appearance improvements. Redesign the toolbar icon for better appearance when using LibreOffice 6 for Windows. Make speech scripts compatible with Ubuntu 18.04 LTS Bionic Beaver. When reading XML code aloud on Linux speech platforms, read the text without the XML tags and attributes. Update the release version string. Change log |
2020-03-05 23:09:47 | Download |
| 0.8.32 | Update links; fix support for Gstreamer sound playing in Linux. | 4.2 | Linux, Windows, macOS | GPL | Update links; fix support for Gstreamer sound playing in Linux. | 2020-03-05 23:09:47 | Download |



★ ★ ★ ☆ ☆
Post your review
You cannot post reviews until you have logged in. Se connecter.
Reviews
Mike Schmitt 19 nov. 2024, 17:55 (Il y a 44 jour)
★ ★ ★ ★ ☆
Hello quick question to the creator. I love this extension and have been using it for about a year with no issue, however recently when I click the read text command it does not show the dialogue option box, it just reads the text
In the past when I would click it it would first open the dialog box and give me options on voices and output and reading speed Etc
I have tried updating uninstalling and reinstalling the program but I still can't seem to get the dialogue box to appear.
How do I reset it to display these options when I click the read extension button?
Thank you
James Holgate 27 nov. 2024, 05:07 (Il y a 37 jour)
The extension hides options that are not available due to permission issues
or a missing program. For example, some releases and variants of Windows do
not include the `wscript.exe` script program that Read Text Extension normally
uses to generate speech.
According to Microsoft…
> VBScript is deprecated. In future releases of Windows, VBScript will
> be available as a feature on demand before its removal from the
> operating system.
-- [Depreciated features in the Windows
Client](https://learn.microsoft.com/en-us/windows/whats-new/deprecated-features).
Microsoft. Accessed January 3, 2024.
Starting with Read Text 0.8.74, the extension uses the LibreOffice and
Apache OpenOffice scripting systems if `wscript.exe` is not available.
The default behavior is to hide the setup menu if your Windows computer
does not support VBScript. You can enable alternative scripting methods
like Python. Use the LibreOffice *Tools - Options - Advanced* dialog and
check *Enable Experimental Features*.
If you are using Windows, it might be possible for you or your computer
administrator to enable or disable VBScript using a command in a
terminal. See “Features On Demand” from
[learn.microsoft.com](https://learn.microsoft.com/en-us/windows-hardware/manufacture/desktop/features-on-demand-v2--capabilities?view=windows-11).
[More…](https://github.com/jimholgate/readtextextension/tree/master/gists/setup_piper)
Kevin Rosteing 19 janv. 2024, 16:11 (Il y a 12 mois)
☆ ☆ ☆ ☆ ☆
For someone who is blind, he/she cannot see the extension icon "Read Text". You should create a ShortKey such as Ctrl + R to read the highlighted text.
James Holgate 23 févr. 2024, 23:21 (Il y a 10 mois)
This extension does not directly support keyboard shortcuts.
However, users can create a keyboard shortcut for a macro by following these steps:
* Go to *Tools > Customize*.
* In the upper right corner, click *LibreOffice* or *Writer* to define the context in which the new shortcut applies.
* In the Customize dialog box, select the *Keyboard* tab.
* In the Shortcut keys section, select an unused key combination that you want to use. (i. e. : *Shift + Space* also known as `SHIFT_SPACE`)
* In the Category list, select *LibreOffice Macros > My Macros > TextToSpeech > TextToSpeech*.
* In the Function list, select *ReadTextAloud*.
* Once the custom keyboard modification is complete, save the custom setting as a `cfg` file so that the custom settings can be restored or used on similar computers.
* Click *OK* to apply the custom setting for the current user.
To restore a custom configuration using the `cfg` file:
* Go to *Tools > Customize*.
* Click *Load*
* Navigate to the configuration file using the file dialog.
* Click *OK*.
* Click *OK*.
[LibreOffice Help][1]
[1]: https://help.libreoffice.org/latest/en-US/text/shared/guide/scripting.html
mike glass 23 févr. 2023, 00:16 (Il y a 23 mois)
★ ★ ★ ★ ☆
It's a great program. It works through my Asus laptop speakers but **it won't work with headphones** either plugged in or Bluetooth. I tried it on my other laptop and it works fine. I thought it worked before on this one. Windows 10 Libreoffice 7.5. I have tried everything I can think of including reinstalling an older version of Libreoffice with no luck. Headphones work fine with other programs. Any thoughts?
James Holgate 17 mars 2023, 16:28 (Il y a 22 mois)
This might help, or it might not. Some laptops come with an audio enhancement app that allows you to set custom audio profiles for different sources, music styles and/or different outputs. You could look for a program with something like "SRS" or "Dolby" in the title to check the settings for headphones. You could also check the Device Manager to see if a different sound card driver solves your problem. Lastly, if the problem started when you updated the application, try using the 32 bit version if you are using the 64 bit version, or vice-versa to see if that helps.
Robert Ferraro 7 déc. 2022, 07:58 (Il y a 2 année)
★ ★ ★ ★ ★
I find this to be an excellent extension and serves me perfectly. A pause feature would be awesome!!
James Holgate 17 mars 2023, 16:59 (Il y a 22 mois)
Thank you for your feedback!
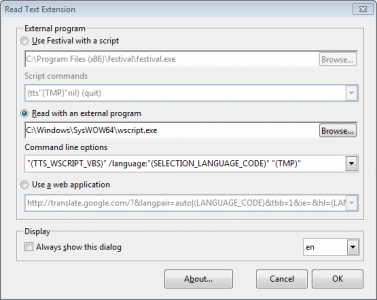
On some platforms, you can get the sound to play in a media player with a command line flag. For example, with Windows 10, use the `visible:"true"` flag...
`"(TTS_WSCRIPT_VBS)" /visible:"true" /language:"(SELECTION_LANGUAGE_COUNTRY_CODE)" "(TMP)"`
Once the sound file opens with the media player, you can pause, rewind, repeat and stop as you like.
The information in the "About" dialog describes the available options for particular speech tools.
joseph 1 nov. 2022, 07:20 (Il y a 2 année)
☆ ☆ ☆ ☆ ☆
Please check what the speaker pronounces.
Pronouncing the character coding.
Example, check five (5) characters:
( ) ' " &
with Kubuntu 22.10 (Kinetic Kudu)
with Libreoffice version 7.4.2.3 and
pico -V
GNU nano, version 6.4
read_text_2022.10.02_06.03.oxt 471.4 KiB (482,748 bytes)
--
James Holgate 17 mars 2023, 16:39 (Il y a 22 mois)
I can't reproduce the problem on Ubuntu 22.04, Fedora 37 or Debian 11. An application in your system appears to interpret XML incorrectly. Try updating your system and revising the extension to the newest version. If you are using a legacy system speech application, you might have better luck using a docker container like MaryTTS.
joseph 18 sept. 2022, 06:59 (Il y a 2 année)
☆ ☆ ☆ ☆ ☆
read_text pronounces characters that ought not be spoken.
Please fix readtext version 0.8.58
In the very least, silence the following 7 characters:
( ) ' " | & _
Because readtext version 0.8.58 says:
( as end-ash-40
) as end-ash-41
& as end-ash-38
etc...
Installed:
read_text version 0.8.58 is installed:
read_text_2022.08.23_20.07.oxt
469.6 KiB (480,834) bytes
and running on:
LibreOffice version 7.3.5.2
and
Operating System: Kubuntu 22.04.1
Please fix readtext version 0.8.58
--
David Katz 13 avr. 2022, 04:56 (Il y a 3 année)
☆ ☆ ☆ ☆ ☆
0.8.52 does not work with 7.3.2.2
Basic Runtime error. Line 4191
James Holgate 17 mars 2023, 16:40 (Il y a 22 mois)
Thanks for the information. I think it is fixed with the current extension and the current version of LibreOffice.
L Duperval 16 mars 2022, 20:47 (Il y a 3 année)
★ ★ ★ ★ ☆
It works well except that I can't find a reliable way for it to use the language code of a paragraph to determine which voice to use.
If someone can provide that information, I can give this a 5-star rating!
David Casey 9 nov. 2021, 02:33 (Il y a 3 année)
★ ★ ★ ☆ ☆
Loved this extension, but it seems to be broken with the new LO 7. Hoping this gets fixed sometime soon.
Scott Ishiyama 21 oct. 2021, 22:54 (Il y a 3 année)
★ ★ ★ ★ ★
Works great in MacOSX Mojave. Simple to install and uses the built-in Speech settings from the Accessibility preferences pane in MacOS.
It works so well that I created an account here just to leave this review.
1 2 suivant »
Il n'y a pas encore de commentaire.
RSS feed for reviews on this page | RSS feed for all reviews